Rotation CIFAR Experiment¶
This experiment will use images from the CIFAR-100 database (https://www.cs.toronto.edu/~kriz/cifar.html) and showcase the backward transfer efficiency of algorithms in the ProgLearn project (https://github.com/neurodata/ProgLearn) as the images are rotated.
[1]:
# Import necessary packages
import numpy as np
from tensorflow import keras
from multiprocessing import Pool
from functools import partial
[2]:
# Create array to store errors
errors_array = []
[3]:
# Loads and reshapes data sets
(X_train, y_train), (X_test, y_test) = keras.datasets.cifar100.load_data()
# Joins the training and testing arrays into one
data_x = np.concatenate([X_train, X_test])
data_y = np.concatenate([y_train, y_test])
data_y = data_y[:, 0]
Hyperparameters¶
Hyperparameters determine how the model will run.
granularity refers to the amount by which the angle will be increased each time. Setting this value at 1 will cause the algorithm to test every whole number rotation angle between 0 and 180 degrees.
reps refers to the number of repetitions tested for each angle of rotation. For each repetition, the data is randomly resampled.
max_depth refers to the maximum depth of each tree in the synergistic forest. If this value is not specified, it defaults to a max tree depth of 30.
[4]:
### MAIN HYPERPARAMS ###
granularity = 4
reps = 10 # use 100 reps for the main draft plot
max_depth = 30
########################
Algorithms¶
The progressive-learning repo contains two main algorithms, Synergistic Forest (SynF) and Synergistic Network (SynN), within forest.py and network.py, respectively. The main difference is that SynF uses random forests while SynN uses deep neural networks. Both algorithms, unlike LwF, EWC, Online_EWC, and SI, have been shown to achieve both forward and backward knowledge transfer.
For the purposes of this experiment, the SynF algorithm will be used.
Experiment¶
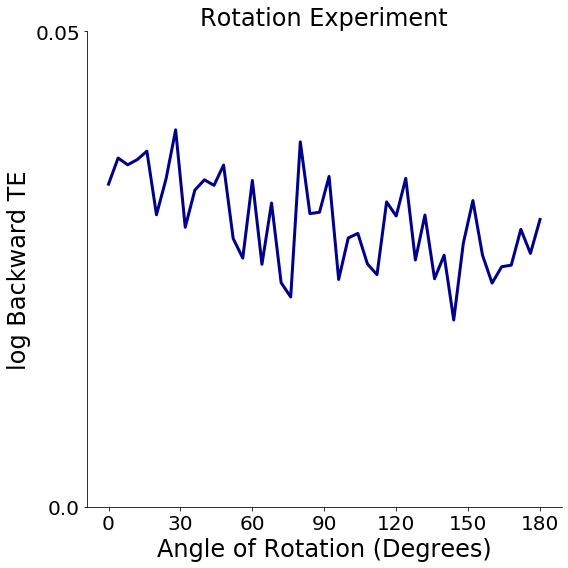
If the chosen algorithm is trained on both straight up-and-down CIFAR images and rotated CIFAR images, rather than just straight up-and-down CIFAR images, will it perform better (achieve a higher backward transfer efficiency) when tested on straight up-and-down CIFAR images? How does the angle at which training images are rotated affect these results?
At a rotation angle of 0 degrees, the rotated images simply provide additional straight up-and-down CIFAR training data, so the backward transfer efficiency at this angle show whether or not the chosen algorithm can even achieve backward knowledge transfer. As the angle of rotation increases, the rotated images become less and less similar to the original dataset, so the backward transfer efficiency should logically decrease, while still being above 1.
[5]:
# SynF
from functions.rotation_cifar_functions import synf_experiment
# Generate set of angles to test for BTE
angles = np.arange(0, 181, granularity)
# Parallel processing
with Pool(48) as p:
# Multiple sets of errors for each set of angles are appended to a larger array containing errors for all angles
# Calling LF_experiment will run the experiment at a new angle of rotation
errors_array.append(
p.map(
partial(
synf_experiment,
data_x=data_x,
data_y=data_y,
reps=reps,
ntrees=10,
acorn=1,
),
angles,
)
)
Rotation CIFAR Plot¶
This section takes the results of the experiment and plots the backward transfer efficiency against the angle of rotation for the images in CIFAR-100.
Expected Results¶
If done correctly, the plot should show that Backward Transfer Efficiency (BTE) is greater than 1 regardless of rotation, but the BTE should decrease as the angle of rotation is increased. The more the number of reps and the finer the granularity, the smoother this downward sloping curve should look.
[6]:
# Calculate BTE for each angle of rotation
bte = []
for angle in angles:
orig_error, transfer_error = errors_array[0][
int(angle / granularity)
] # (angle/granularity) gives the index of the errors for that angle
bte.append(
orig_error / transfer_error
) # (original error/transfer error) gives the BTE
[11]:
# Plot angle of rotation vs. BTE
from functions.rotation_cifar_functions import plot_bte
plot_bte(bte, angles)
FAQs¶
Why am I getting an “out of memory” error?¶
Pool(8) in the previous cell allows for parallel processing, so the number within the parenthesis should be, at max, the number of cores in the device on which this notebook is being run. Even if a warning is produced, the results of the experimented should not be affected.
Why is this taking so long to run? How can I speed it up to see if I am getting the expected outputs?¶
Decreasing the value of reps, decreasing the value of max_depth, or increasing the value of granularity will all decrease runtime at the cost of noisier results.